Process billions of rows with distributed efficiency
Optimized execution for complete queries
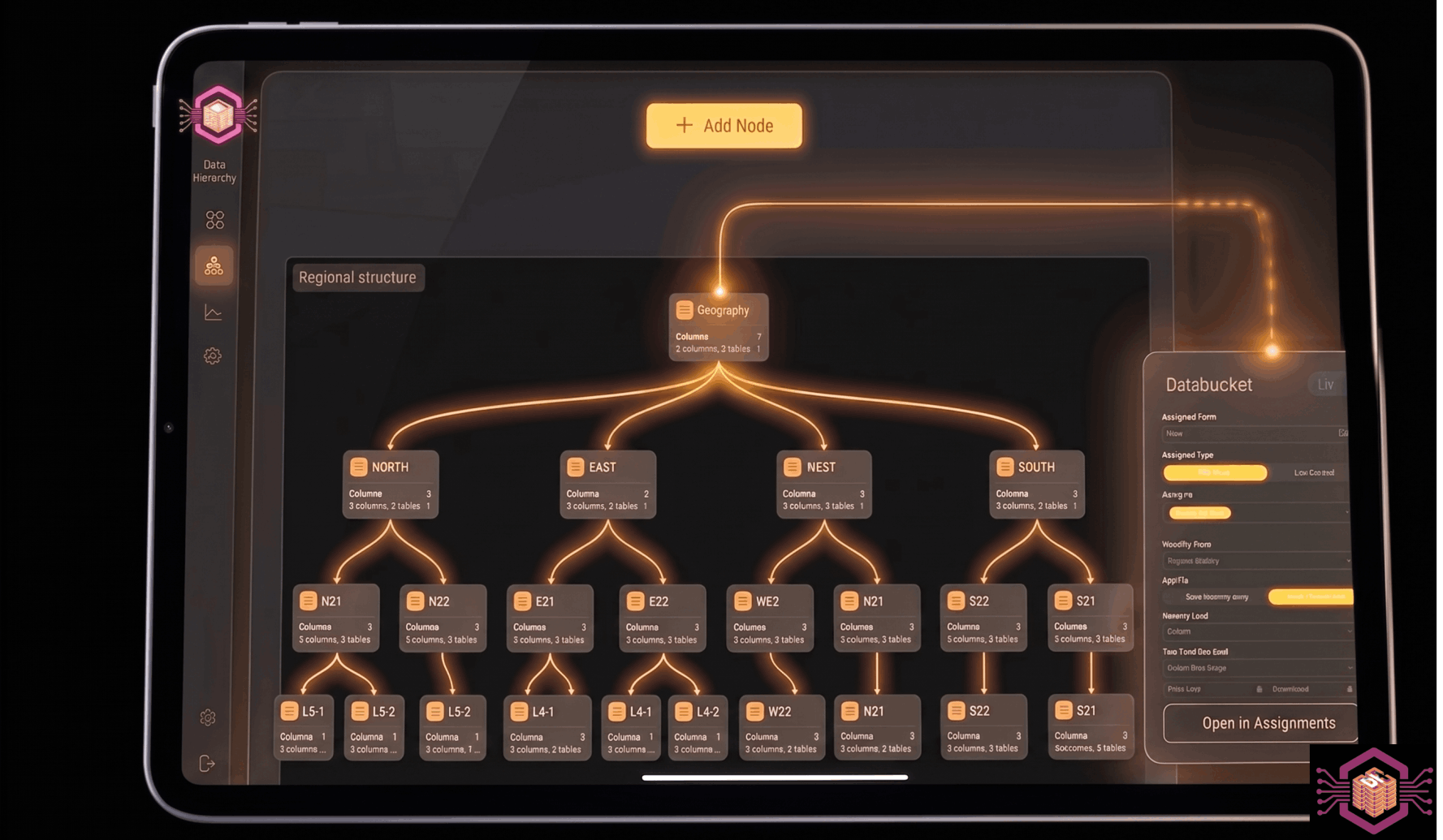
Scale storage and compute seamlessly with demand
Automated, continuous data availability
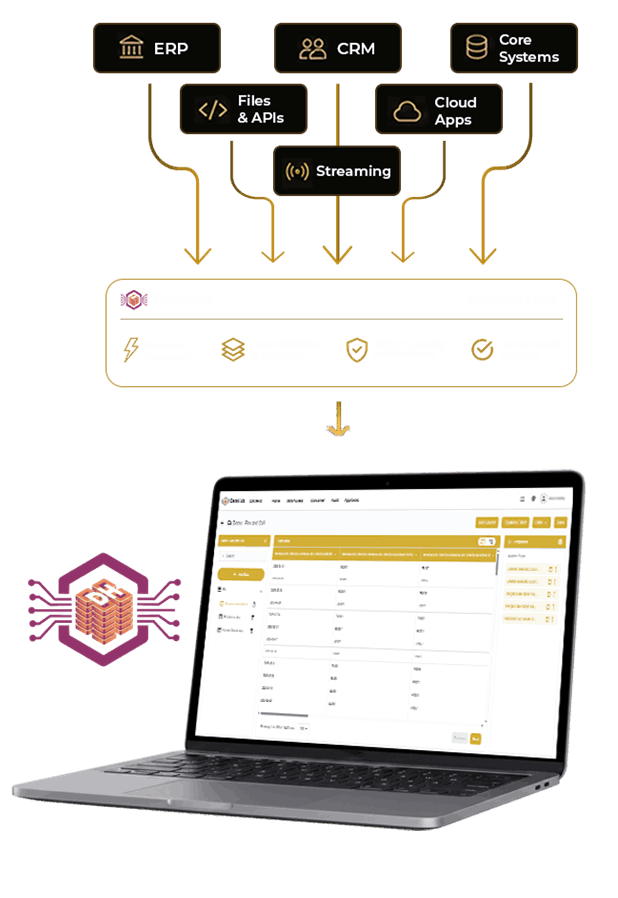
Capture only what's changed. Reduce load, cost and latency
Keep Databuckets current with near real-time data pipelines
No write back. Source systems remain untouched and safe
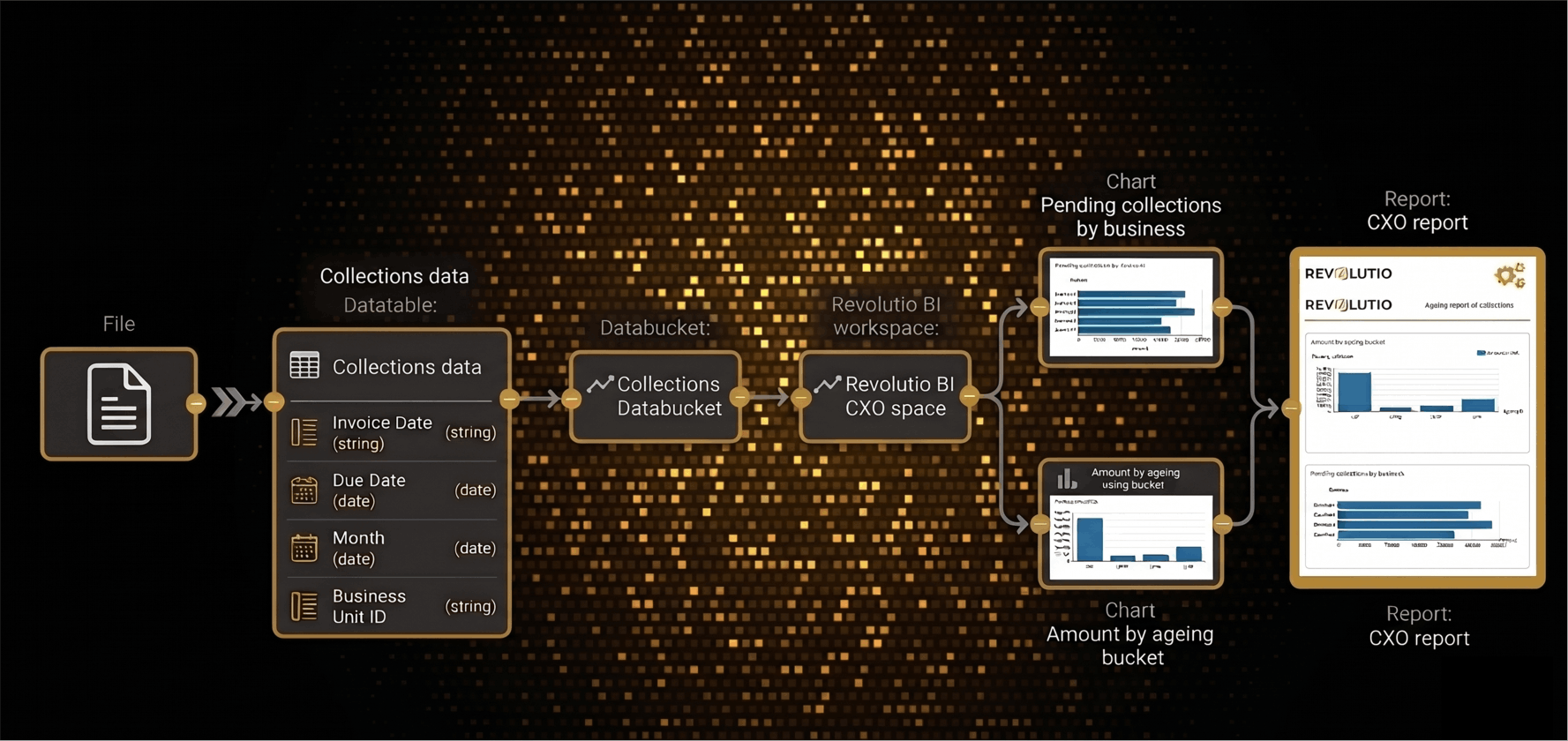
Unified, trusted data ready for analytics, AI and operations
Connect new sources in minutes with pre-built connectors
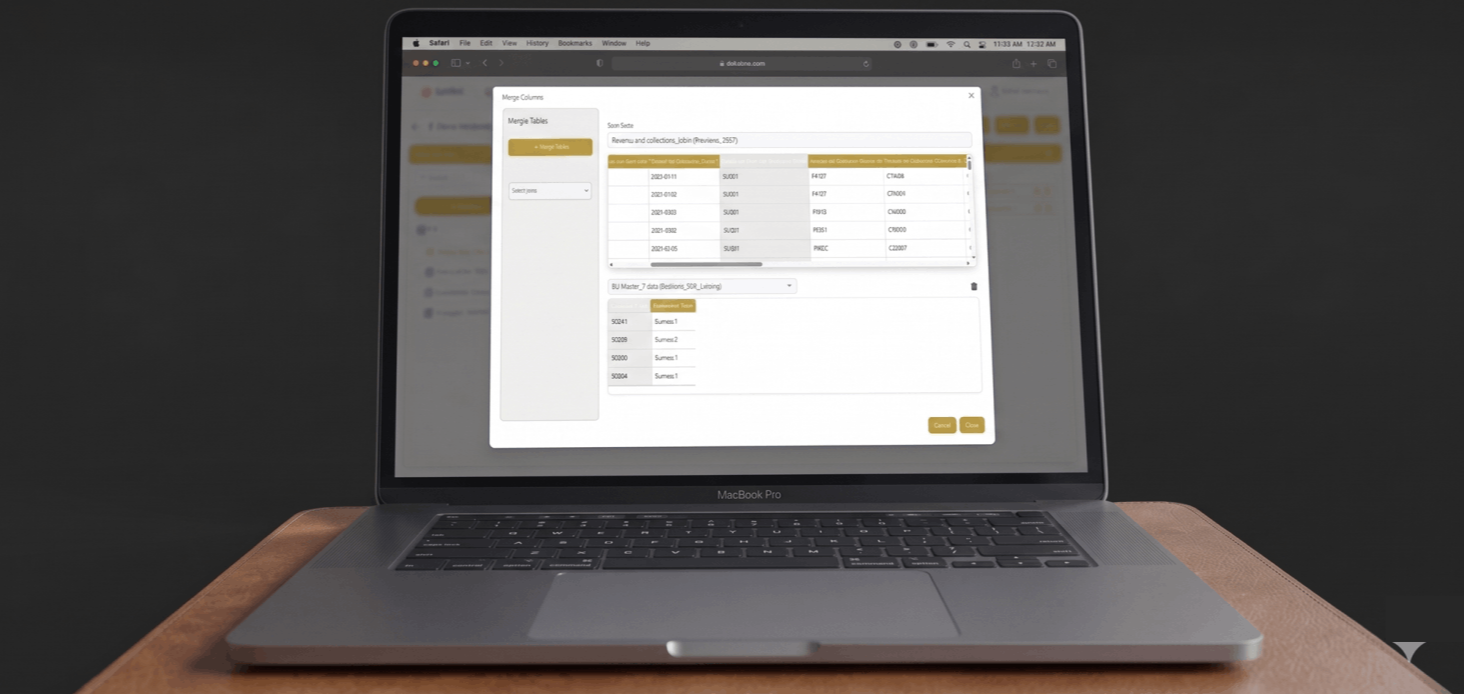
Cleanse data, create derived data, apply business logic and data transformations to your dataset visually.